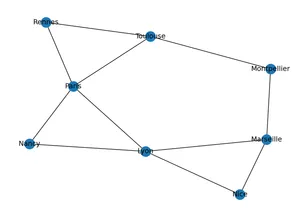
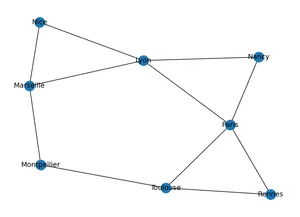
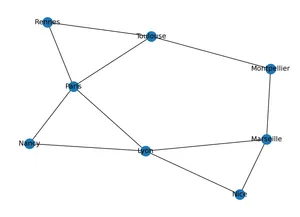
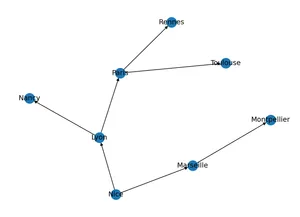
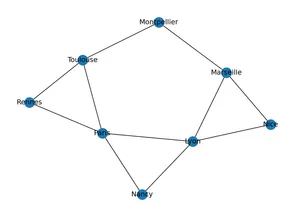
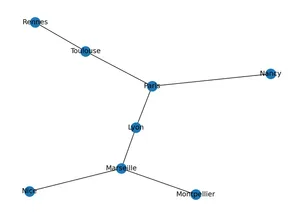
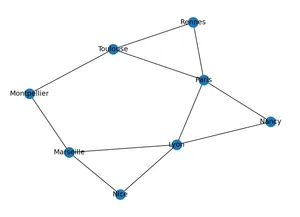
import matplotlib.pyplot as plt # pour les représentations graphiques
import networkx as nx
def create_graph():
G = nx.Graph()
# Ajout des noeuds nommés dans l'ordre alphabétique
for ville in [
"Lyon",
"Marseille",
"Montpellier",
"Nancy",
"Nice",
"Paris",
"Rennes",
"Toulouse",
]:
G.add_node(ville)
# Ajout des arêtes dans l'ordre alphabétique
for voisin in ["Marseille", "Nancy", "Nice", "Paris"]:
G.add_edge("Lyon", voisin)
# Ajout des arêtes dans l'ordre alphabétique
for voisin in [
"Montpellier",
"Nice",
]:
G.add_edge("Marseille", voisin)
G.add_edge("Montpellier", "Toulouse")
G.add_edge("Nancy", "Paris")
G.add_edge("Paris", "Rennes")
G.add_edge("Paris", "Toulouse")
G.add_edge("Rennes", "Toulouse")
return G
# création du graph
G = create_graph()
# Représentation graphique
nx.draw(G, with_labels=True) # Il s'agit du graphe et non d'une carte!